걸음마부터 달리기
DB-집계함수 , 쿼리실행순서 본문
쿼리 실행 순서는 아래와 같다.
FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY > LIMIT/OFFSET
이거때문에 집계함수가 WHERE 절에는 올 수가 없다. 왜냐하면 집계함수를 쓸려면 어찌됐든 GROUP BY 로 인한 그룹화 이후에 써야하는데 GROUP BY보다 WHERE절 실행이 먼저라 그룹화 이전이기 때문이다.
추가) 만약 같은 절 안에서 서브쿼리가 있을 경우 해당 서브쿼리가 메인쿼리보다 먼저 수행된다.
HAVING AVG(P.HEIGHT) < (SELECT AVG(HEIGHT) FROM PLAYER WHERE TEAM_ID ='K02') 에서
일단 메인쿼리의 순서대로 FROM , WHERE 등등 하다가 HAVING절까지 오면 그 HAVING 절 안에서 서브쿼리의 연산이 우선된다.
여러 행들의 그룹(GROUP BY)이 모여서 그룹당 단 하나의 결과를 돌려주는 다중행 함수 중 집계 함수(Aggregate Function)의 특성은 다음과 같다.
- 여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 함수이다.
- GROUP BY 절은 행들을 소그룹화 한다.
- SELECT 절, HAVING 절, ORDER BY 절 에 사용할 수 있다.
함수에 행이 여러개 들어와도 결과값은 오로지 하나다.
집계 함수명 ( [DISTINCT | ALL] 칼럼이나 표현식 )
- ALL : Default 옵션이므로 생략 가능함 - DISTINCT : 같은 값을 하나의 데이터로 간주할 때 사용하는 옵션임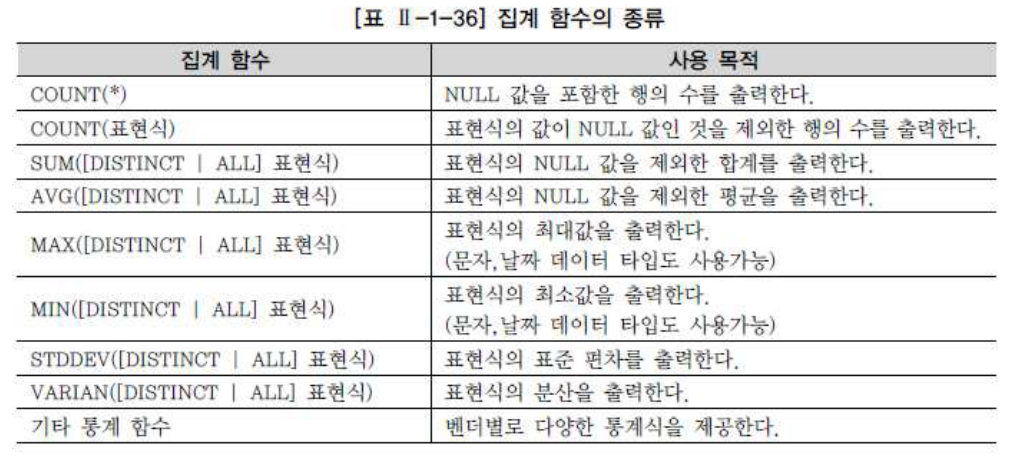
COUNT(*) 와 COUNT(표현식)의 차이점은 NULL의 포함여부이다.
*는 와일드카드로 모든 행을 뜻하지만 모든 속성값이 NULL인 튜플은 존재할수 없기에 사실상 COUNT(*)도 NULL값을 제외하는 것이여도 의미가 없다.
반대로 COUNT(표현식)은 특정 행의 속성값이 NULL일수는 있기에 NULL인 행을 제외하기에 의미가 있다.
항상 중요한건 결국 그룹당 하나의 결과를 리턴하는게 집계함수라는거다.
이러한 그룹으로 묶을때는 GROUP BY를 사용한다.
GROUP BY
GROUP BY 는 같은 값을 가진 행끼리 하나의 그룹으로 뭉쳐준다. 즉 어떤 칼럼에서 칼럼값들이 같으면 그룹시켜서 표시한다. 이는 시각적으로 하나의 행으로 표기한다는 것과 같다.
다음과 같은 특성을 가진다.
- GROUP BY 절을 통해 소그룹별 기준을 정한 후, SELECT 절에 집계 함수를 사용한다.
- 집계 함수의 통계 정보는 NULL 값을 가진 행을 제외하고 수행한다.
- GROUP BY 절에서는 SELECT 절과는 달리 ALIAS 명을 사용할 수 없다.
- 집계 함수는 WHERE 절에는 올 수 없다. (집계 함수를 사용할 수 있는 GROUP BY 절 보다 WHERE 절이 먼저 수행된다) - WHERE 절은 전체 데이터를 GROUP으로 나누기 전에 행들을 미리 제거시킨다.
- HAVING 절은 GROUP BY 절의 기준 항목 이나 소그룹의 집계 함수를 이용한 조건을 표시할 수 있다.
- GROUP BY 절에 의한 소그룹별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어 조건을 만족하는 내용만 출력한다.
- HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치한다.
GROUP BY는 FROM 절과 WHERE절 뒤에 온다.
SELECT [DISTINCT] 칼럼명 [ALIAS명]
FROM 테이블명
[WHERE 조건식]
[GROUP BY 칼럼(Column)이나 표현식]
[HAVING 그룹조건식] ;
HAVING
HAVING은 GROUP BY의 WHERE이라고 생각하면 된다. 특정 행의 값들이 같은것끼리 그룹화되면서 묶인 GROUP BY 이후에 HAVING으로 GROUP BY 안에서도 조건에 해당하는 데이터만 볼 수 있다.
굳이 HAVING이 있는 이유는 GROUP BY로 그룹화 시킨 각각에서 원하는 데이터들만 뽑아서 보고싶은데, 여기서 WHERE절을 GROUP BY와 함께 써버리면 SQL 실행 순서에 따라 WHERE절이 먼저, GROUP BY가 나중에 실행되게 된다. 따라서 우리가 하고싶은 GROUP BY의 그룹 중에서 일부 데이터 추출이 불가능하기에 HAVING절이 따로 있는거다.
SELECT POSITION 포지션, AVG(HEIGHT) 평균키 FROM PLAYER GROUP BY POSITION 포지션;이 SQL문은 에러가 나는데 GROUP BY에서는 ALIAS를 사용하지 못한다. 따라서 GROUP BY POSITION은 가능하지만 뒤에 "포지션"에서 에러가 발생한다.
SELECT POSITION 포지션, ROUND(AVG(HEIGHT),2) 평균키
FROM PLAYER
WHERE AVG(HEIGHT) >= 180
GROUP BY POSITION;
는 에러가 발생한다. 이유는 AVG는 집계함수이기에 GROUP에 대해서만 수행이 가능한데 WHERE은 GROUP BY보다
먼저 수행되기에 불가능하다.
따라서 GROUP BY와 관련한 데이터 추출에서는 2가지 방법이 있을 수 있다.
1) WHERE절로 미리 뽑고 그 뽑아낸 데이터에 대해 GROUP BY를 수행하여 그룹화
2) GROUP BY로 그룹화하고 그 각각의 그룹화 안에서 HAVING절로 데이터 거르기
효율적인 측면에서는 1번이 더 좋다. 왜냐하면 WHERE절로 미리 뽑아낸 상황에서 적어진 데이터로 GROUP BY를 수행하는 것이 더 효율적이기 때문이다. 2번같은 경우는 전체 튜플에 대해서 GROUP BY를 수행하고, 다시 각각의 그룹, 즉 이것도 전체 튜플에 대해서 HAVING으로 걸러내야되기 때문이다.
책에 보면
"여기서 주의할 것은 WHERE 절의 조건 변경은 대상 데이터의 개수가 변경되므로 결과 데이터 값이 변경될 수 있지만, HAVING 절의 조건 변경은 결과 데이터 변경은 없고 출력되는 레코드의 개수만 변경될 수 있다."
라고 나와있는데 잘 이해가 가진 않지만 뇌피셜을 끄적여보겠다.
WHERE절은 우선 기존 테이블에서 데이터를 필터링하여 가져오고, 그걸 바탕으로 GROUP BY를 수행한다.
하지만 HAVING절은 모든 데이터를 우선 GROUP BY 해놓고 그 그룹화된 전체 데이터 안에서 HAVING으로 필터링을 한다.
필터링 한 후 GROUP BY와 전체에서 GROUP BY한 후 필터링의 차이점은 아래와 같다.
WHERE절
SELECT
date,
SUM(amount) AS total_amount
FROM
sales
WHERE
location = 'Seoul'
GROUP BY
date;HAVING절
SELECT
date,
SUM(amount) AS total_amount
FROM
sales
GROUP BY
date
HAVING
SUM(CASE WHEN location = 'Seoul' THEN amount ELSE 0 END) > 0;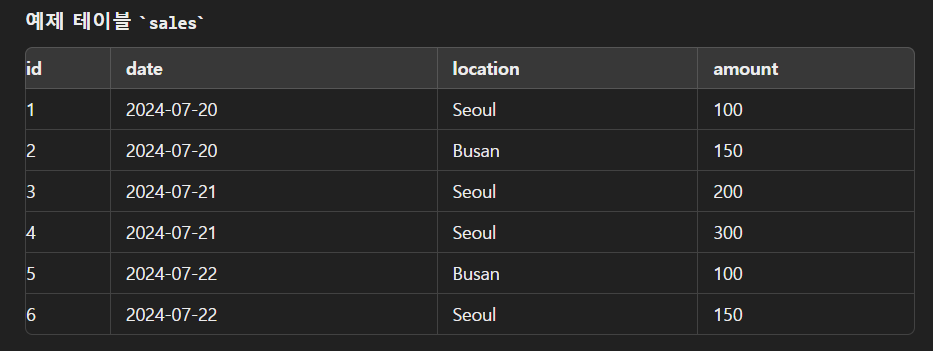
이때 한번 생각해보자.
WHERE절 포함의 SQL 결과는

HAVING절 포함의 SQL 결과는

이다.
WHERE에서는 우선 SEOUL이 아닌것들을 다 거른다. 그 후 남은 데이터(SEOUL인것)에서 GROUP BY로 그룹화를 하고 SUM을 진행하면 서울에서 각 DATE에 따른 TOTAL AMOUNT가 나온다.
하지만 HAVING 절에서는 먼저 GROUP BY를 해버리니까 같은 DATE로 그룹화된 데이터들 안에는 SEOUL , BUSAN 등등 전부 들어가있다. 이때 HAVING절로 인해 SUM을 하는것까진 기존에 각 DATE에 따라 서울에서 팔린 TOTAL AMOUNT를 관찰하고 싶은 현재의 목적과 동일한데, SELECT문에서 SUM(AMOUNT)를 써버리면 필터링 없이 전체 데이터에 대한 AMOUNT가 수행되므로 SEOUL만 필터링이 안된다. 그래서 2024-7-20일의 TOTAL_AMOUNT가 100(SEOUL)+150(BUSAN)인 것이다.
WHERE은 조건 수행의 대상 데이터가 변경될 수 있고 HAVING은 조건 수행의 데이터가 변경되지 않는다는것이 이말이다.
CASE 표현을 활용한 월별 데이터 집계
??
집계함수와 NULL 처리
다중행 함수 연산을 위해 NULL값이 포함되어 있는 단일행들을 모두 NVL로 NULL값을 특정 값으로 바꾸고 다중행 연산을 시도하는데 이것은 매우 비효율적이다. (모든 행이 NULL일경우 집계함수를 통한 결과값이 NULL이 나오는것을 방지하기 위해서 먼저 NVL을 통해 NULL값을 다 바꿔주는 행위를 하는거)
왜냐하면 다중행 함수는 해당 행의 연산에 필요한 열의 모든 값이 NULL일때만 NULL로 판단한다. 한 열의 값이 NULL이 아니면 그것은 다중행에서 NULL이 아니다.
따라서 NVL로 NULL값을 다 바꿔버리면 그건 NULL로 다중행에서 판단을 안하고 불필요한 데이터까지 연산을 수행해야 된다. (다중 행에서도 그 행들이 모두 NULL이라서 NULL로 인식되는데 굳이 NVL로 NULL을 실제 숫자값을 바꿔서 이것도 연산에 포함시켜버리면 오버헤드가 늘어난다는거)
CASE 표현 사용시 ELSE절을 생략하면 DEFAULT 값이 NULL이다. 따라서 우선 CASE를 먼저 사용하여 NULL값은 NULL로 냅둔 상황에서 집계함수를 써 NULL은 연산에서 제외시킨다. 이러한 집계함수 연산 이후에 각각의 다중행값이 NULL이고, 모든 행들이 NULL일때 집계함수는 NULL이기에 이 NULL을 바꿔주기 위해 추후 NVL을 수행하면 된다는거다.
