걸음마부터 달리기
DB-서브쿼리 본문
서브쿼리(Subquery)란 하나의 SQL문안에 포함되어 있는 또 다른 SQL문을 말한다.
조인은 조인에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다. 그 러나 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다.
예를들면
SELECT employee_id, employee_name , department_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE department_name LIKE 'Sales%'
);이러한 sql문이 있다고 가정하자. 메인쿼리에서는 서브쿼리(테이블) 의 칼럼을 참조 못하는 대신에 서브쿼리에서는 메인쿼리(테이블)의 칼럼 참조가 가능하다. 따라서 메인쿼리의 department_name의 칼럼은 서브쿼리 테이블의 칼럼이기에 문제가 생긴다는 것이다.
이럴때는 조인같이 애초에 테이블 2개를 참조하는 sql문을 사용해야한다는 것이다.
서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성된다. 당연하게도 서브쿼리의 결과가 결국엔 메인쿼리의 조건으로 사용되기에 메인쿼리 레벨에서 동작된다는 것이다.
특징:- 서브쿼리는 단일 행(Single Row) 또는 복수 행(Multiple Row) 비교 연산자와 함께 사용 가능하다. 단일 행 비교 연 산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관 없다. - 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY절은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인쿼리의 마지막 문장에 위치해야 한다.

서브쿼리는 3가지의 데이터 형태를 반환 가능하다.
단일행 서브쿼리 :
서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>)와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다.
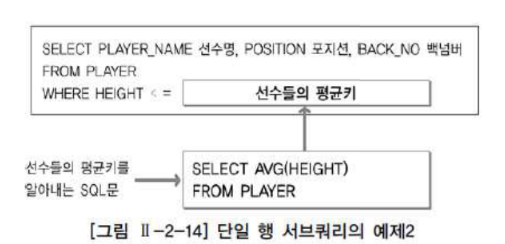
SELECT PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = (SELECT TEAM_ID FROM PLAYER WHERE PLAYER_NAME = '정남일')
ORDER BY PLAYER_NAME;이게 단일행 서브쿼리인데 서브쿼리의 결과로 이름이 정남일이라는 사람의 TEAM_ID가 선택됨을 알 수 있다.
웃긴건 만약에 정남일이라는 동명이인이 있어서 2건 이상 결과가 반환되었다면 SQL문은 오류가 발생한다.
집계함수를 사용하여 서브쿼리에서 반환값을 한개로 줄여서 나타낼 수도 있다.
갑자기 생각난게 집계함수를 Group by의 그룹함수와 같이 써야만된다고 생각하고 있었는데 아니다.
집계함수는 단 하나의 결과값을 리턴해주는건 맞지만 Group By 없이도 사용 가능하다.
다중 행 서브쿼리
서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용해야 한다.

SELECT REGION_NAME 연고지명, TEAM_NAME 팀명, E_TEAM_NAME 영문팀명
FROM TEAM
WHERE TEAM_ID = (SELECT TEAM_ID FROM PLAYER W HERE PLAYER_NAME = '정현수')
ORDER BY TEAM_NAME;
반환이 다중행이라 단일행 비교 연산자랑은 불가능
SELECT REGION_NAME 연고지명, TEAM_NAME 팀명, E_TEAM_NAME 영문팀명
FROM TEAM
WHERE TEAM_ID IN (SELECT TEAM_ID FROM PLAYER WHERE PLAYER_NAME = '정현수')
ORDER BY TEAM_NAME;
다중 칼럼 서브쿼리
다중 칼럼 서브쿼리는 서브쿼리의 결과로 여러 개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미한다
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE (TEAM_ID, HEIGHT) IN
(SELECT TEAM_ID, MIN(HEIGHT)
FROM PLAYER
GROUP BY TEAM_ID)
ORDER BY TEAM_ID, PLAYER_NAME;SQL문의 실행 결과를 보면 서브쿼리의 결과값으로 소속팀코드(TEAM_ID)와 소속팀별 가장 작은 키를 의미하는 MIN(HEIGHT)라는 두 개의 칼럼을 반환했다. 메인쿼리에서는 조건절에 TEAM_ID와 HEIGHT 칼럼을 괄호로 묶어서 서브쿼리 결과와 비교하여 원하는 결과를 얻었다
연관 서브쿼리
연관 서브쿼리(Correlated Subquery)는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다
SELECT T.TEAM_NAME 팀명, M.PLAYER_NAME 선수명, M.POSITION 포지션, M.BACK_NO 백넘버, M.HEIGHT 키
FROM PLAYER M, TEAM T
WHERE M.TEAM_ID = T.TEAM_ID
AND M.HEIGHT <
(SELECT AVG(S.HEIGHT)
FROM PLAYER S WHERE S.TEAM_ID = M.TEAM_ID
AND S.HEIGHT IS NOT NULL
GROUP BY S.TEAM_ID )
ORDER BY 선수명;S.TEAM_ID = M.TEAM_ID 처럼 서브쿼리 내에서 메인쿼리 칼럼이 사용되면 연관서브쿼리의 분류이다.
다시 말하지만 서브쿼리 내에서는 메인쿼리의 칼럼 참조가 가능하지만 반대는 불가능하다.
스칼라 서브쿼리(Scalar Subquery)
SELECT 절에서 사용하는 서브쿼리인 스칼라 서브쿼리(Scalar Subquery)에 대해서 알아본다.
스칼라 서브쿼리는 한 행, 한 칼럼(1 Row 1 Column)만을 반환하는 서브쿼리를 말한다.

헷갈리는 부분은 다음과 같다.
SELECT문에서 나오는 칼럼들은 같은 행의 갯수를 가져야된다고 알고 있다.
PLAYER_NAME과 HEIGHT는 PLAYER 라는 같은 테이블의 열이니까 같은 행의 갯수를 가지고 있을 것이다.
근데 뒤에 오는 SELECT 서브쿼리를 보면 어찌됐든 AVG(HEIGHT)면 단 하나의 행을 반환할텐데 이러니까 지금 스칼라 서브쿼리라고 하는거 아닌가?
그러면 서로의 칼럼이 행 갯수가 안맞는데 이럴때는 SELECT 연산을 어떻게 하는가??
뇌피셜
연관서브쿼리가 매우 중요하다. 책을 기준으로 공부했을때는 책에 연관서브쿼리에 관한 내용이 그냥 서브쿼리에서 메인서브쿼리의 칼럼을 참조하면 연관서브쿼리라고 했다. 근데 그것보다 더 중요한건 연관서브쿼리일때는 쿼리 연산을 메인쿼리 연산의 각 행에 대하여 한번씩 서브쿼리를 수행한다는 것이다.
위의 예시에서도보면 P.TEAM_ID로 메인쿼리의 칼럼을 참조하고 있는 연관서브쿼리이자 스칼라 서브쿼리이다. 그러다보니 서브쿼리의 결과인 행 갯수와 메인쿼리 SELECT문에 오는 칼럼의 행 갯수는 서로 달라도 메인 쿼리의 결과에 대하여 각 행마다 서브쿼리를 수행한다.
FROM 절에서 서브쿼리 사용하기
FROM 절에서 사용되는 서브쿼리를 인라인 뷰(Inline View)라고 한다. FROM 절에는 테이블 명이 오도록 되어 있다. 그런데 서브쿼리의 결과가 마치 실행 시에 동적으로 생성된 테이블인 것처럼 사용할 수 있다. 인라인 뷰는 SQL문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 일반적인 뷰를 정적 뷰(Static View)라고 하고 인라인 뷰를 동적 뷰(Dynamic Vie w)라고도 한다.
SELECT T.TEAM_NAME 팀명, P.PLAYER_NAME 선수명, P.BACK_NO 백넘버
FROM (SELECT TEAM_ID, PLAYER_NAME, BACK_NO FROM PLAYER WH ERE POSITION = 'MF') P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID ORDER BY 선수명;이때는 SELECT 서브쿼리로 만들어지는 칼럼들을 참조 가능하다.
HAVING 절에서 서브쿼리 사용하기
HAVING 절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용한다
SELECT P.TEAM_ID 팀코드, T.TEAM_NAME 팀명, AVG(P.HEIGHT) 평균키
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID
GROUP BY P.TEAM_ID, T.TEAM_NAME
HAVING AVG(P.HEIGHT) < (SELECT AVG(HEIGHT) FROM PLAYER WHERE TEAM_ID ='K02')
팀코드 팀명 평균키
---- ----------- ------
K13 강원FC 173.667
K15 대구FC 175.333
K11 경남FC 176.333
K14 제주유나이티드FC 169.5
K12 광주상무 17 3.5
K07 드래곤즈 178.391
K08 일화천마 178.854
K10 시티즌 177.485
8개의 행이 선택되었다.참으로 복잡한 쿼리이다. 일단 FROM으로 조인을 하고 있는데 WHERE로 인해서 TEAM_ID가 같은것으로 조인을 한다.
그 다음 GROUP BY로 P.TEAM_ID와 T.TEAM_NAME이 모두 같은 것끼리 그룹화한다. 그 다음 여기까지의 데이터를 보고 서브쿼리를 우선 연산 후 각 그룹에서 AVG(P.HEIGHT)값이 서브쿼리의 결과보다 작으면 해당 그룹을 선택하고 아니면 버린다. 그 다음에는 메인쿼리의 SELECT대로 출력한다.
INSERT문의 VALUES절에서 사용하기
INSERT
INTO PLAYER(PLAYER_ID, PLAYER_NAME, TEAM_ID)
VALUES((SELECT TO_CHAR(MAX(TO_NUMBER(PLAYER_ID))+1) FROM PLAYER), '홍길동', 'K 06');
뷰(View)
테이블은 실제로 데이터를 가지고 있는 반면, 뷰(View)는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰 정의(View Definition)만을 가지고 있다. 질의에서 뷰 가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성(뷰가 아닌 기존 테이블에 대한 쿼리) (Rewrite)하여 질의를 수행한다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하 는 역할을 수행하기 때문에 가상 테이블(Virtual Table)이라고도 한다.
CREATE VIEW문을 통해서 생성할 수 있다.
뷰를 제거하기 위해서는 DROP VIEW문을 사용한다.
